The web’s clipboard, and how it stores data of different types
If you’ve been using computers for a while, you probably know that the clipboard can store multiple types of data (images, rich text content, files, and so on). As a software developer, it started frustrating me that I didn’t have a good understanding of how the clipboard stores and organizes data of different types.
I recently decided to unveil the mystery that is the clipboard and wrote this post using my learnings. We’ll focus on the web clipboard and its APIs, though we’ll also touch on how it interacts with operating system clipboards.
We’ll start by exploring the web’s clipboard APIs and their history. The clipboard APIs have some interesting limitations around data types, and we’ll see how some companies have worked around those limitations. We’ll also look at some proposals that aim to resolve those limitations (most notably, Web Custom Formats).
If you’ve ever wondered how the web’s clipboard works, this post is for you.
Using the async Clipboard API
If I copy some content from a website and paste it into Google Docs, some of its formatting is retained, such as links, font size, and color.
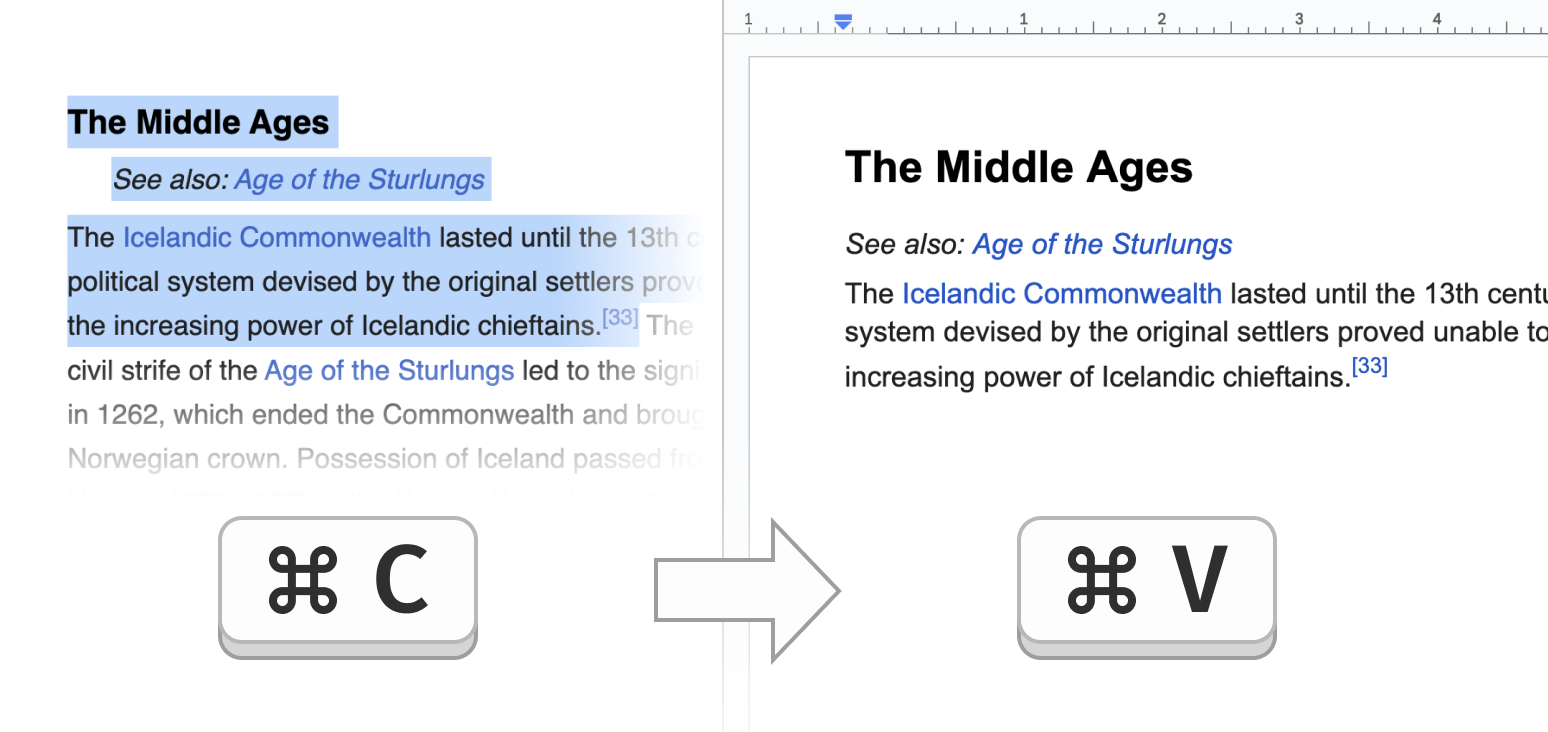
But if I open VS Code and paste it there, only the raw text content is pasted.
The clipboard serves these two use cases by allowing information to be stored in multiple representations associated with MIME types. The W3C Clipboard spec mandates that for writing to and reading from the clipboard, these three data types must be supported:
text/plainfor plain text.text/htmlfor HTML.image/pngfor PNG images.
So when I pasted before, Google Docs read the text/html representation and used that to retain the rich text formatting. VS Code only cares about the raw text and reads the text/plain representation. Makes sense.
Reading a specific representation via the async Clipboard API’s read method is quite straightforward:
const items = await navigator.clipboard.read();for (const item of items) {if (item.types.includes("text/html")) {const blob = await item.getType("text/html");const html = await blob.text();// Do stuff with HTML...}}
Writing multiple representations to the clipboard via write is a bit more involved, but still relatively straightforward. First, we construct Blobs for each representation that we want to write to the clipboard:
const textBlob = new Blob(["Hello, world"], { type: "text/plain" });const htmlBlob = new Blob(["Hello, <em>world<em>"], { type: "text/html" });
Once we have the blobs, we pass them to a new ClipboardItem in a key-value store with the data types as the keys and the blobs as the values:
const clipboardItem = new ClipboardItem({[textBlob.type]: textBlob,[htmlBlob.type]: htmlBlob,});
Note: I like that ClipboardItem accepts a key-value store. It nicely aligns with the idea of using a data structure that makes illegal states unrepresentable, as discussed in Parse, don’t validate.
Finally, we invoke write with our newly constructed ClipboardItem:
await navigator.clipboard.write([clipboardItem]);
What about other data types?
HTML and images are cool, but what about general data interchange formats like JSON? If I were writing an application with copy-paste support, I could imagine wanting to write JSON or some binary data to the clipboard.
Let’s try to write JSON data to the clipboard:
// Create JSON blobconst json = JSON.stringify({ message: "Hello" });const blob = new Blob([json], { type: "application/json" });// Write JSON blob to clipboardconst clipboardItem = new ClipboardItem({ [blob.type]: blob });await navigator.clipboard.write([clipboardItem]);
Upon running this, an exception is thrown:
Failed to execute 'write' on 'Clipboard':Type application/json not supported on write.
Hmm, what’s up with that? Well, the spec for write tells us that data types other than text/plain, text/html, and image/png must be rejected:
If type is not in the mandatory data types list, then reject [...] and abort these steps.
Interestingly, the application/json MIME type was in the mandatory data types list from 2012 to 2021 but was removed from the spec in w3c/clipboard-apis#155. Prior to that change, the lists of mandatory data types were much longer, with 16 mandatory data types for reading from the clipboard, and 8 for writing to it. After the change, only text/plain, text/html, and image/png remained.
This change was made after browsers opted not to support many of the mandatory types due to security concerns. This is reflected by a warning in the mandatory data types section in the spec:
Warning! The data types that untrusted scripts are allowed to write to the clipboard are limited as a security precaution.
Untrusted scripts can attempt to exploit security vulnerabilities in local software by placing data known to trigger those vulnerabilities on the clipboard.
Okay, so we can only write a limited set of data types to the clipboard. But what’s that about “untrusted scripts”? Can we somehow run code in a “trusted” script that lets us write other data types to the clipboard?
The isTrusted property
Perhaps the “trusted” part refers to the isTrusted property on events. isTrusted is a read-only property that is only set to true if the event was dispatched by the user agent.
document.addEventListener("copy", (e) => {if (e.isTrusted) {// This event was triggered by the user agent}})
Being “dispatched by the user agent” means that it was triggered by the user, such as a copy event triggered by the user pressing Command C. This is in contrast to a synthetic event programmatically dispatched via dispatchEvent():
document.addEventListener("copy", (e) => {console.log("e.isTrusted is " + e.isTrusted);});document.dispatchEvent(new ClipboardEvent("copy"));//=> "e.isTrusted is false"
Let’s look at the clipboard events and see whether they allow us to write arbitrary data types to the clipboard.
The Clipboard Events API
A ClipboardEvent is dispatched for copy, cut, and paste events, and it contains a clipboardData property of type DataTransfer. The DataTransfer object is used by the Clipboard Events API to hold multiple representations of data.
Writing to the clipboard in a copy event is very straightforward:
document.addEventListener("copy", (e) => {e.preventDefault(); // Prevent default copy behaviore.clipboardData.setData("text/plain", "Hello, world");e.clipboardData.setData("text/html", "Hello, <em>world</em>");});
And reading from the clipboard in a paste event is just as simple:
document.addEventListener("paste", (e) => {e.preventDefault(); // Prevent default paste behaviorconst html = e.clipboardData.getData("text/html");if (html) {// Do stuff with HTML...}});
Now for the big question: can we write JSON to the clipboard?
document.addEventListener("copy", (e) => {e.preventDefault();const json = JSON.stringify({ message: "Hello" });e.clipboardData.setData("application/json", json); // No error});
No exception is thrown, but did this actually write the JSON to the clipboard? Let’s verify that by writing a paste handler that iterates over all of the entries in the clipboard and logs them out:
document.addEventListener("paste", (e) => {for (const item of e.clipboardData.items) {const { kind, type } = item;if (kind === "string") {item.getAsString((content) => {console.log({ type, content });});}}});
Adding both of these handlers and invoking copy-paste results in the following being logged:
{ "type": "application/json", content: "{\"message\":\"Hello\"}" }
It works! It seems that clipboardData.setData does not restrict data types in the same manner as the async write method does.
But... why? Why can we read and write arbitrary data types using clipboardData but not when using the async Clipboard API?
History of clipboardData
The relatively new async Clipboard API was added to the spec in 2017, but clipboardData is much older than that. A W3C draft for the Clipboard API from 2006 defines clipboardData and its setData and getData methods (which shows us that MIME types were not being used at that point):
setData()This takes one or two parameters. The first must be set to either ‘text’ or ‘URL’ (case-insensitive).
getData()This takes one parameter, that allows the target to request a specific type of data.
But it turns out that clipboardData is even older than the 2006 draft. Look at this quote from the “Status of this Document” section:
In large part [this document] describes the functionalities as implemented in Internet Explorer...
The intention of this document is [...] to specify what actually works in current browsers, or [be] a simple target for them to improve interoperability, rather than adding new features.
This 2003 article details how, at the time, in Internet Explorer 4 and above, you could use clipboardData to read the user’s clipboard without their consent. Since Internet Explorer 4 was released in 1997 it seems that the clipboardData interface is at least 26 years old at the time of writing.
MIME types entered the spec in 2011:
The dataType argument is a string, for example but not limited to a MIME type...
If a script calls getData(‘text/html’)...
At the time, the spec had not determined which data types should be used:
While it is possible to use any string for setData()‘s type argument, sticking to common types is recommended.
[Issue] Should we list some “common types”?
Being able to use any string for setData and getData still holds today. This works perfectly fine:
document.addEventListener("copy", (e) => {e.preventDefault();e.clipboardData.setData("foo bar baz", "Hello, world");});document.addEventListener("paste", (e) => {const content = e.clipboardData.getData("foo bar baz");if (content) {console.log(content); // Logs "Hello, world!"}});
If you paste this code snippet into your DevTools and then hit copy and paste, you will see the message “Hello, world” logged to your console.
The reason for the Clipboard Events API’s clipboardData allowing us to use any data type seems to be a historical one. “Don’t break the web”.
Revisiting isTrusted
Let’s consider this sentence from the mandatory data types section again:
The data types that untrusted scripts are allowed to write to the clipboard are limited as a security precaution.
So what happens if we attempt to write to the clipboard in a synthetic (untrusted) clipboard event?
document.addEventListener("copy", (e) => {e.preventDefault();e.clipboardData.setData("text/plain", "Hello");});document.dispatchEvent(new ClipboardEvent("copy", {clipboardData: new DataTransfer(),}));
This runs successfully, but it doesn’t modify the clipboard. This is the expected behavior as explained in the spec:
Synthetic cut and copy events must not modify data on the system clipboard.
Synthetic paste events must not give a script access to data on the real system clipboard.
So only copy and paste events dispatched by the user agent are allowed to modify the clipboard. Makes total sense—I wouldn’t want websites to freely read my clipboard contents and steal my passwords.
To summarize our findings so far:
- The async Clipboard API introduced in 2017 restricts which data types can be written to and read from the clipboard. However, it can read from and write to the clipboard at any time, given that the user has granted permission to do so (and the document is focused).
- The older Clipboard Events API has no real restrictions on which data types can be written to and read from the clipboard. However, it can only be used in copy and paste event handlers triggered by the user agent (i.e. when
isTrustedis true).
It seems that using the Clipboard Events API is the only way forward if you want to write data types to the clipboard that are not just plain text, HTML, or images. It’s much less restrictive in that regard.
But what if you want to build a Copy button that writes non-standard data types to the clipboard? It doesn’t seem like you’d be able to use the Clipboard Events API if the user did not trigger a copy event. Right?
Building a copy button that writes arbitrary data types
I went and tried out Copy buttons in different web applications and inspected what was written to the clipboard. It yielded interesting results.
Google Docs has a Copy button which can be found in their right-click menu.
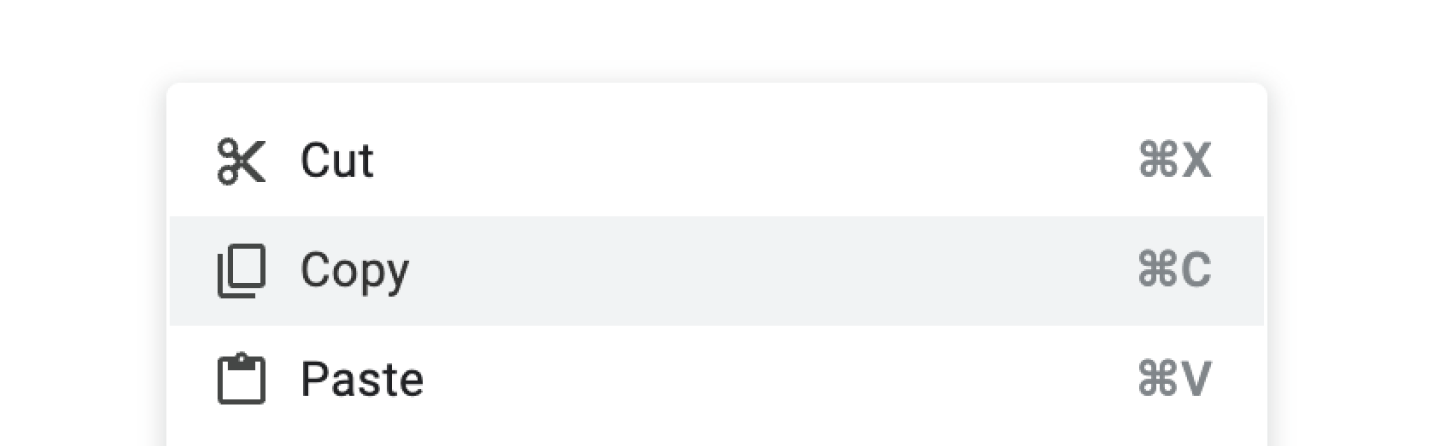
This copy button writes three representations to the clipboard:
text/plain,text/html, andapplication/x-vnd.google-docs-document-slice-clip+wrapped
Note: The third representation contains JSON data.
They’re writing a custom data type to the clipboard, which means that they aren’t using the async Clipboard API. How are they doing that through a click handler?
I ran the profiler, hit the copy button, and inspected the results. It turns out that clicking the copy button triggers a call to document.execCommand("copy").
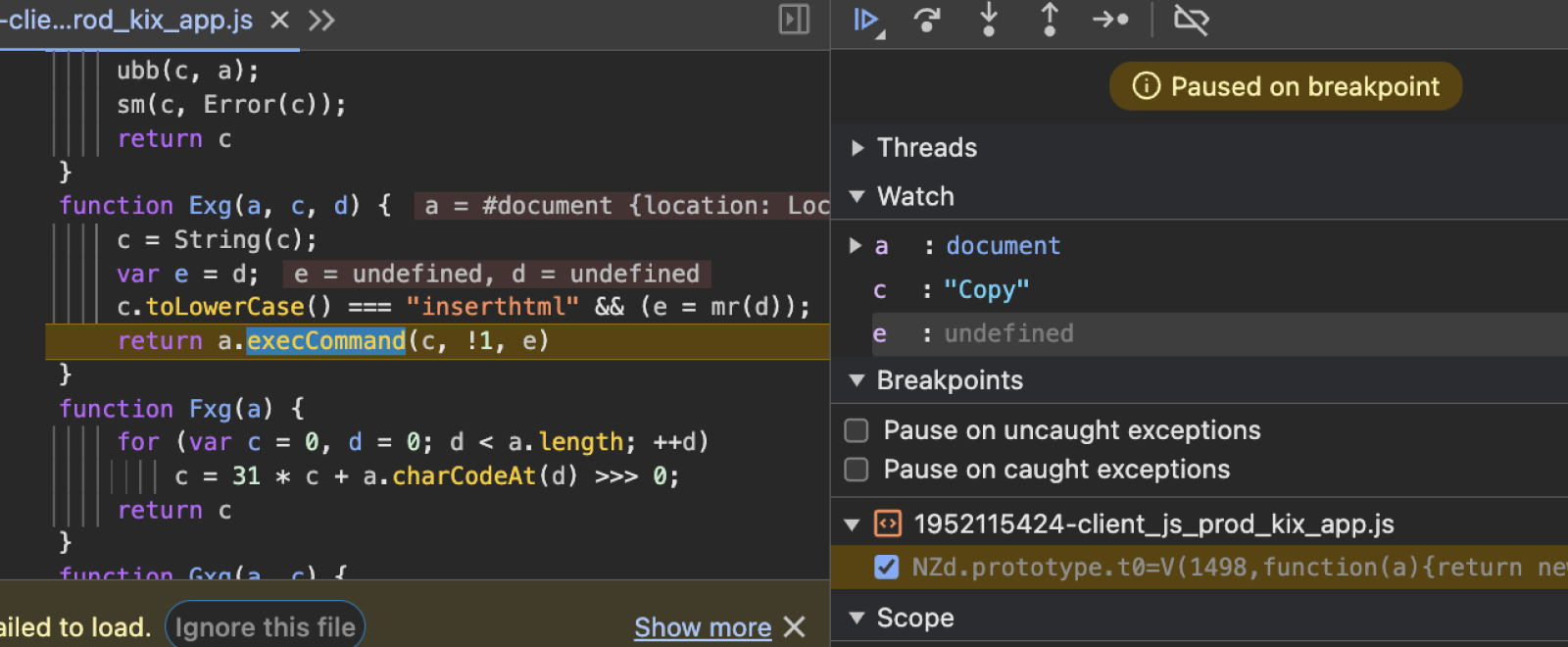
This was surprising to me. My first thought was “Isn’t execCommand the old, deprecated way of copying text to the clipboard?”.
Yes, it is, but Google uses it for a reason. execCommand is special in that it allows you to programmatically dispatch a trusted copy event as if the user invoked the copy command themselves.
document.addEventListener("copy", (e) => {console.log("e.isTrusted is " + e.isTrusted);});document.execCommand("copy");//=> "e.isTrusted is true"
Note: Safari requires an active selection for execCommand("copy") to dispatch a copy event. That selection can be faked by adding a non-empty input element to the DOM and selecting it prior to invoking execCommand("copy"), after which the input can be removed from the DOM.
Okay, so using execCommand allows us to write arbitrary data types to the clipboard in response to click events. Cool!
What about paste? Can we use execCommand("paste")?
Building a paste button
Let’s try the Paste button in Google Docs and see what it does.
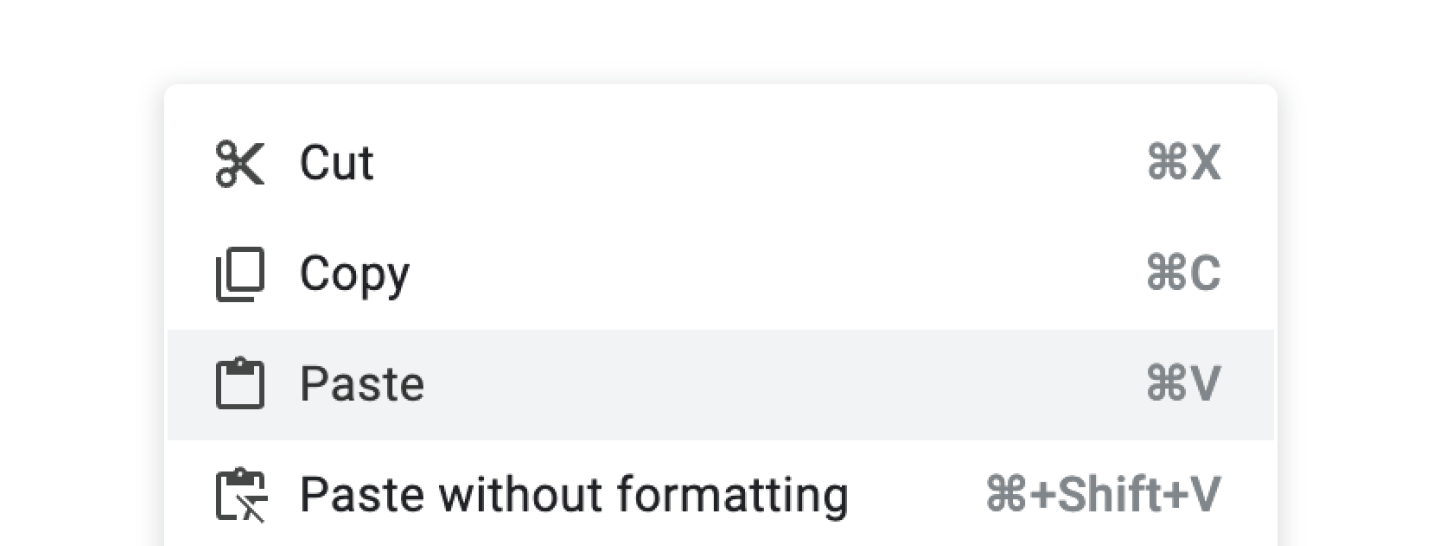
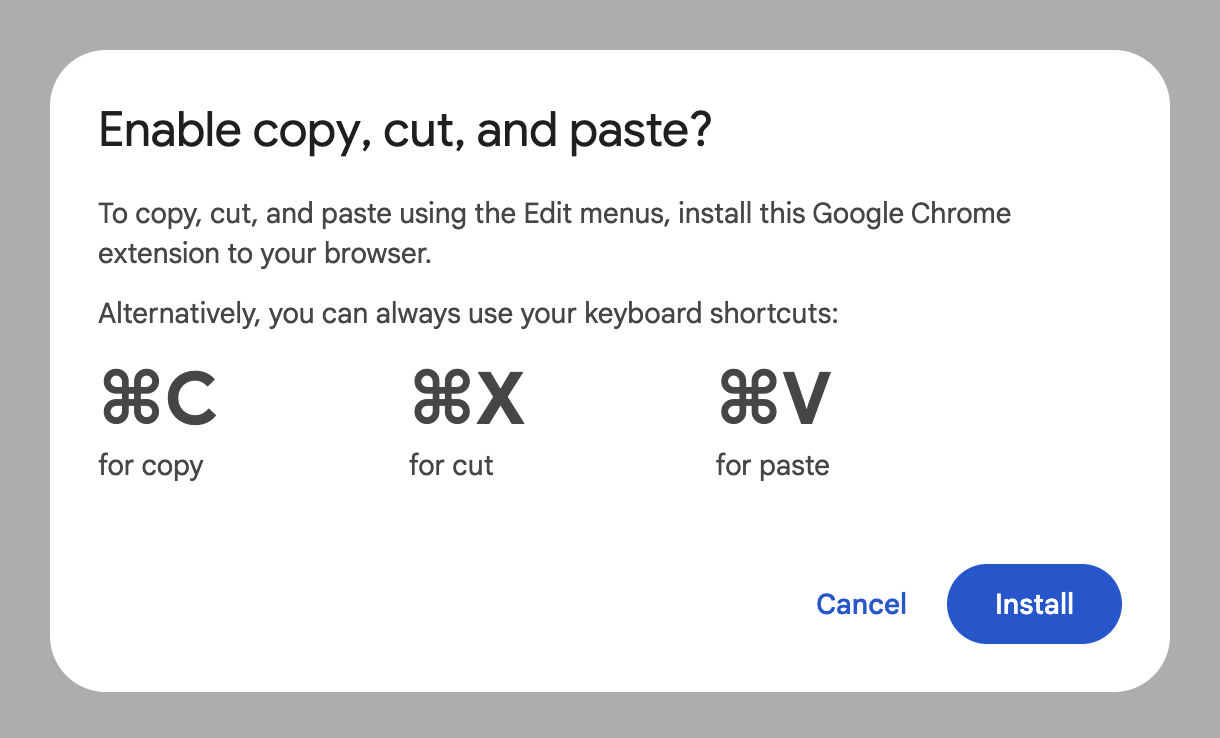
On my Macbook, I got a popup telling me that I need to install an extension to use the paste button.
But oddly, on my Windows laptop, the paste button just worked.
Weird. Where does the inconsistency come from? Well, whether or not the paste button will work can be checked by running queryCommandSupported("paste"):
document.queryCommandSupported("paste");
On my Macbook, I got false on Chrome and Firefox, but true on Safari.
Safari, being privacy-conscious, required me to confirm the paste action. I think that’s a really good idea. It makes it very explicit that the website will read from your clipboard.
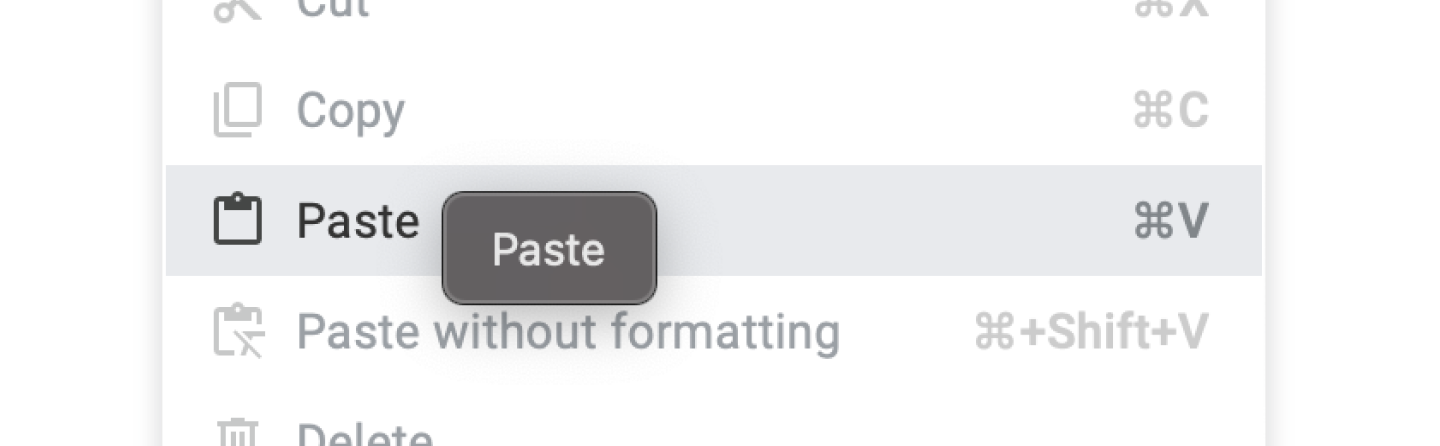
On my Windows laptop, I got true on Chrome and Edge, but false on Firefox. The inconsistency with Chrome is surprising. Why does Chrome allow execCommand("paste") on Windows but not macOS? I wasn’t able to find any info on this.
I find it surprising that Google doesn’t attempt to fall back to the async Clipboard API when execCommand("paste") is unavailable. Even though they wouldn’t be able to read the application/x-vnd.google-[...] representation using it, the HTML representation contains internal IDs that could be used.
<!-- HTML representation, cleaned up --><meta charset="utf-8"><b id="docs-internal-guid-[guid]" style="..."><span style="...">Copied text</span></b>
Another web application with a paste button is Figma, and they take a completely different approach. Let’s see what they’re doing.
Copy and Paste in Figma
Figma is a web-based application (their native app uses Electron). Let’s see what their copy button writes to the clipboard.
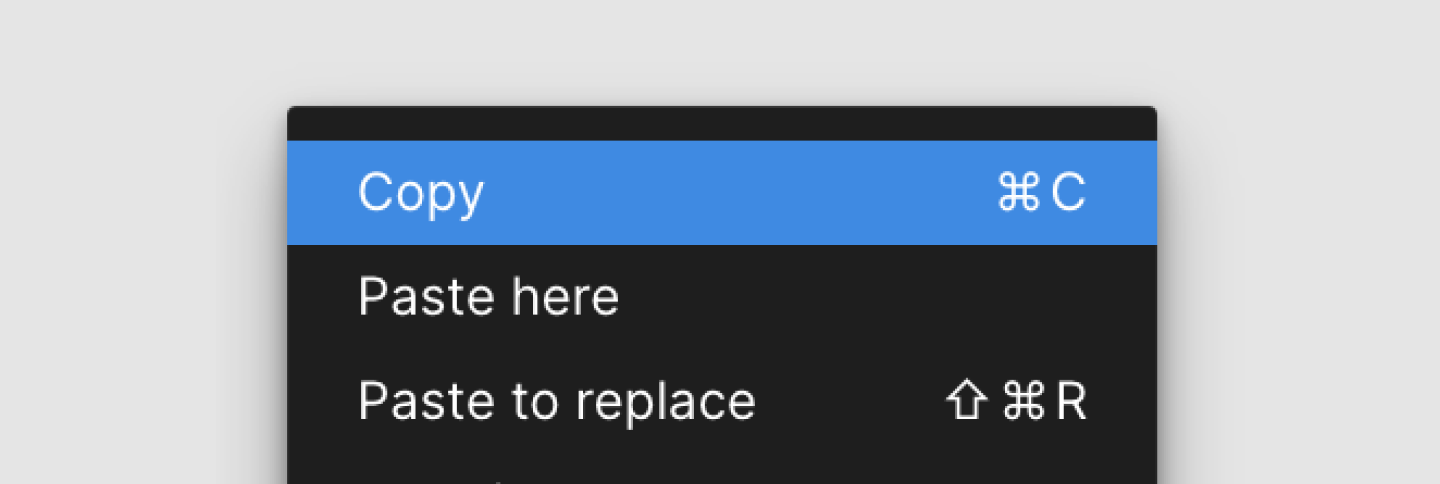
Figma’s copy button writes two representations to the clipboard: text/plain and text/html. This was surprising to me at first. How would Figma represent their various layout and styling features in plain HTML?
But looking at the HTML, we see two empty span elements with data-metadata and data-buffer properties:
<meta charset="utf-8"><div><span data-metadata="<!--(figmeta)eyJma[...]9ifQo=(/figmeta)-->"></span><span data-buffer="<!--(figma)ZmlnL[...]P/Ag==(/figma)-->"></span></div><span style="white-space:pre-wrap;">Text</span>
Note: The data-buffer string is ~26,000 characters for an empty frame. After that, the length of data-buffer seems to grow linearly with the amount of content that was copied.
Looks like base64. The eyJ start is a clear indication of data-metadata being a base64 encoded JSON string. Running JSON.parse(atob()) on data-metadata yields:
{"fileKey": "4XvKUK38NtRPZASgUJiZ87","pasteID": 1261442360,"dataType": "scene"}
Note: I’ve replaced the real fileKey and pasteID.
But what about the big data-buffer property? Base64 decoding it yields the following:
fig-kiwiF\x00\x00\x00\x1CK\x00\x00µ½\v\x9CdI[...]\x197Ü\x83\x03
Looks like a binary format. After a bit of digging—using fig-kiwi as a clue—I discovered that this is the Kiwi message format (created by Figma’s co-founder and former CTO, Evan Wallace), which is used to encode .fig files.
Since Kiwi is a schema-based format, it seemed like we wouldn’t be able to parse this data without knowing the schema. However, lucky for us, Evan created a public .fig file parser. Let’s try plugging the buffer into that!
To convert the buffer into a .fig file, I wrote a small script to generate a Blob URL:
const base64 = "ZmlnL[...]P/Ag==";const blob = base64toBlob(base64, "application/octet-stream");console.log(URL.createObjectURL(blob));//=> blob:<origin>/1fdf7c0a-5b56-4cb5-b7c0-fb665122b2ab
I then downloaded the resulting blob as a .fig file, uploaded that to the .fig file parser, and voilà:
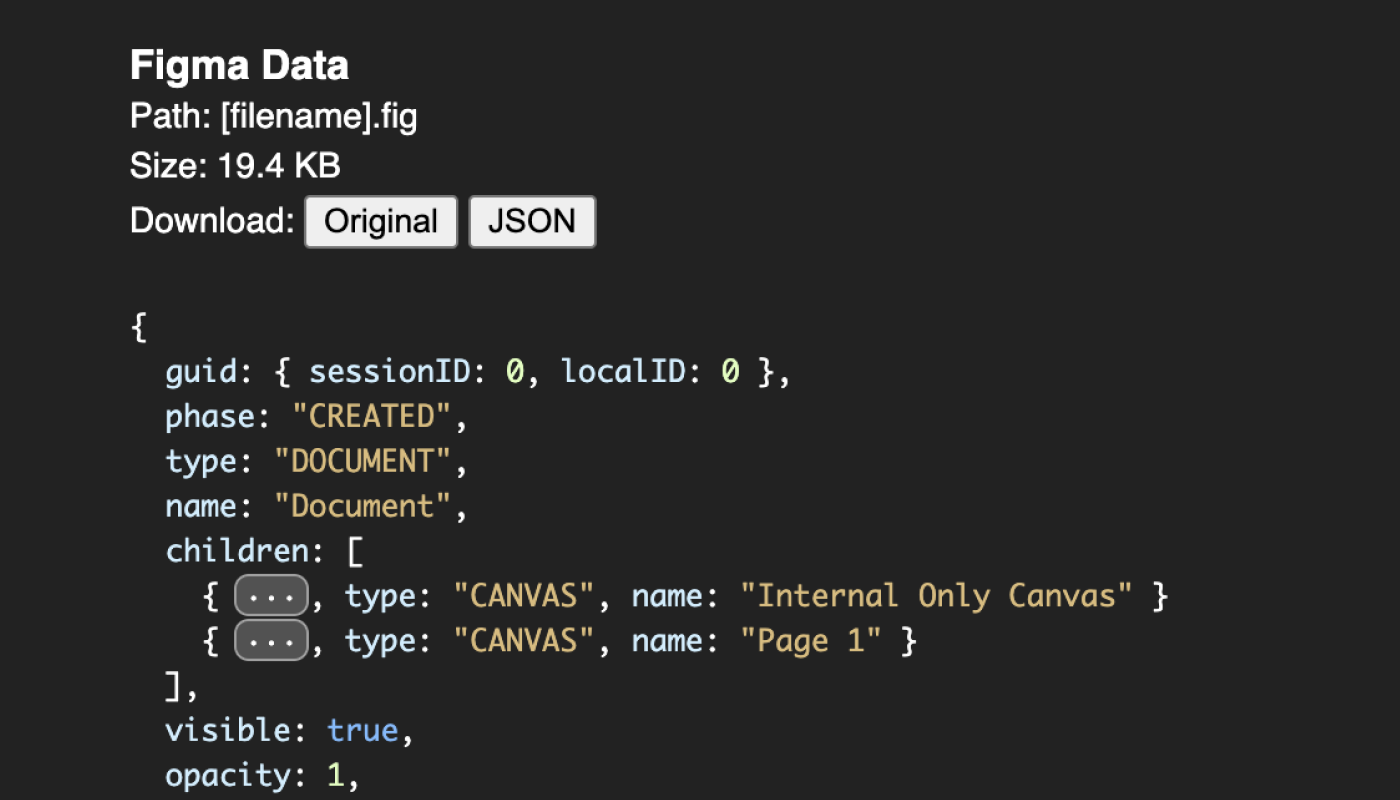
So copying in Figma works by creating a small Figma file, encoding that as a base64, placing the resulting base64 string into the data-buffer attribute of an empty HTML span element, and storing that in the user’s clipboard.
The benefits of copy-pasting HTML
This seemed a bit silly to me at first, but there is a strong benefit to taking that approach. To understand why, consider how the web-based Clipboard API interacts with the various operating system Clipboard APIs.
Windows, macOS, and Linux all offer different formats for writing data to the clipboard. If you want to write HTML to the clipboard, Windows has CF_HTML and macOS has NSPasteboard.PasteboardType.html.
All of the operating systems offer types for “standard” formats (plain text, HTML, and PNG images). But which OS format should the browser use when the user attempts to write an arbitrary data type like application/foo-bar to the clipboard?
There isn’t a good match, so the browser doesn’t write that representation to common formats on the OS clipboard. Instead, that representation only exists within a custom browser-specific clipboard format on the OS clipboard. This results in being able to copy and paste arbitrary data types across browser tabs, but not across applications.
This is why using the common data types text/plain, text/html and image/png is so convenient. They are mapped to common OS clipboard formats and as such can be easily read by other applications, which makes copy/paste work across applications. In Figma’s case, using text/html enables copying a Figma element from figma.com in the browser and then pasting it into the native Figma app, and vice versa.
What do browsers write to the clipboard for custom data types?
We’ve learned that we can write and read custom data types to and from the clipboard across browser tabs, but not across applications. But what exactly are browsers writing to the native OS clipboard when we write custom data types to the web clipboard?
I ran the following in a copy listener in each of the major browsers on my Macbook:
document.addEventListener("copy", (e) => {e.preventDefault();e.clipboardData.setData("text/plain", "Hello, world");e.clipboardData.setData("text/html", "<em>Hello, world</em>");e.clipboardData.setData("application/json", JSON.stringify({ type: "Hello, world" }));e.clipboardData.setData("foo bar baz", "Hello, world");});
I then inspected the clipboard using Pasteboard Viewer. Chrome adds four entries to the Pasteboard:
public.htmlcontains the HTML representation.public.utf8-plain-textcontains the plain text representation.org.chromium.web-custom-datacontains the custom representations.org.chromium.source-urlcontains the URL of the web page where the copy was performed.
Looking at the org.chromium.web-custom-data, we see the data we copied:
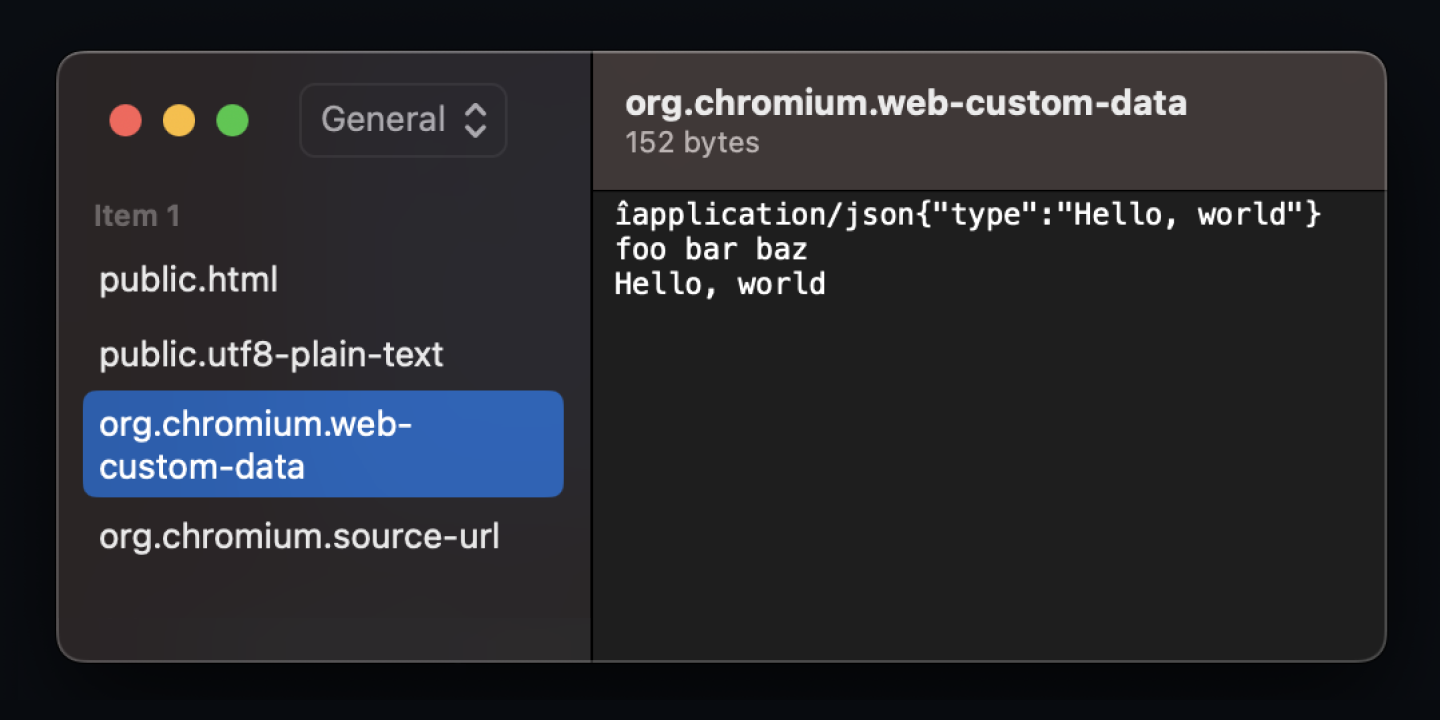
I imagine the accented “î” and inconsistent line breaks are the result of some delimiters being displayed incorrectly.
Firefox creates the public.html and public.utf8-plain-text entries as well, but writes the custom data to org.mozilla.custom-clipdata. It does not store the source URL like Chrome does.
Safari, as you might expect, also creates the public.html and public.utf8-plain-text entries. It writes the custom data to com.apple.WebKit.custom-pasteboard-data and, interestingly, it also stores the full list of representations (including plain text and HTML) and source URL there.
Note: Safari allows copy-pasting custom data types across browser tabs if the source URL (domain) is the same, but not across different domains. This limitation does not seem to be present in Chrome or Firefox (even though Chrome stores the source URL).
Raw Clipboard Access for the Web
A proposal for Raw Clipboard Access was created in 2019, which proposed an API for giving web applications raw read and write access to the native OS clipboards.
This excerpt from the Motivation section on chromestatus.com for the Raw Clipboard Access feature highlights the benefits rather succinctly:
Without Raw Clipboard Access [...] web applications are generally limited to a small subset of formats, and are unable to interoperate with the long tail of formats. For example, Figma and Photopea are unable to interoperate with most image formats.
However, the Raw Clipboard Access proposal ended up not being taken further due to security concerns around exploits such as remote code execution in native applications.
The most recent proposal for writing custom data types to the clipboard is the Web Custom Formats proposal (often referred to as pickling).
Web Custom Formats (Pickling)
In 2022, Chromium implemented support for Web Custom Formats in the async Clipboard API.
It allows web applications to write custom data types via the async Clipboard API by prefixing the data type with "web ":
// Create JSON blobconst json = JSON.stringify({ message: "Hello, world" });const jsonBlob = new Blob([json], { type: "application/json" });// Write JSON blob to clipboard as a Web Custom Formatconst clipboardItem = new ClipboardItem({[`web ${jsonBlob.type}`]: jsonBlob,});navigator.clipboard.write([clipboardItem]);
These are read using the async Clipboard API like any other data type:
const items = await navigator.clipboard.read();for (const item of items) {if (item.types.includes("web application/json")) {const blob = await item.getType("web application/json");const json = await blob.text();// Do stuff with JSON...}}
What’s more interesting is what is written to the native clipboard. When writing web custom formats, the following is written to the native OS clipboard:
- A mapping from the data types to clipboard entry names
- Clipboard entries for each data type
On macOS, the mapping is written to org.w3.web-custom-format.map and its content looks like so:
{"application/json": "org.w3.web-custom-format.type-0","application/octet-stream": "org.w3.web-custom-format.type-1"}
The org.w3.web-custom-format.type-[index] keys correspond to entries on the OS clipboard containing the unsanitized data from the blobs. This allows native applications to look at the mapping to see if a given representation is available and then read the unsanitized content from the corresponding clipboard entry.
Note: Windows and Linux use a different naming convention for the mapping and clipboard entries.
This avoids the security issues around raw clipboard access since web applications cannot write unsanitized data to whatever OS clipboard format they want to. That comes with an interoperability trade-off that is explicitly listed in the Pickling for Async Clipboard API spec:
Non-goals
Allow interoperability with legacy native applications, without update. This was explored in a raw clipboard proposal, and may be explored further in the future, but comes with significant security challenges (remote code execution in system native applications).
This means that native applications need to be updated for clipboard interop with web applications when using custom data types.
Web Custom Formats have been available in Chromium-based browsers since 2022, but other browsers have not implemented this proposal yet.
Final words
As of right now, there isn’t a great way to write custom data types to the clipboard that works across all browsers. Figma’s approach of placing base64 strings into an HTML representation is crude but effective in that it circumvents the plethora of limitations around the clipboard API. It seems like a good approach to take if you need to transmit custom data types via the clipboard.
I find the Web Custom Formats proposal promising, and I hope it becomes implemented by all of the major browsers. It seems like it would enable writing custom data types to the clipboard in a secure and practical manner.
Thanks for reading! I hope this was interesting.
— Alex Harri
Appendix: the unsanitized option
When reading from the clipboard via the async Clipboard API, browsers may sanitize the data. For example, browsers may strip potentially dangerous script tags from HTML, and they may re-encode PNG images to avoid zip bomb attacks.
For this reason, the async Clipboard API’s read method contains an unsanitized option that allows you to request the unsanitized data. You can read more about this option and how it works in this post from Thomas Steiner.
Currently, the unsanitized option is only supported in Chromium-based browsers (added in late 2023). The other browsers may support this option in the future (though Safari seems unlikely to do so, see Stakeholder Feedback/Opposition).
Thanks, Tom, for reaching out in regards to mentioning the unsanitized option! It fits well within the scope of this post.
To be notified of new posts, subscribe to my mailing list.