Making GRID’s spreadsheet engine 10% faster
GRID’s product sports a feature-complete spreadsheet engine running in the browser, with advanced features such as spilling, iterative calculation, and the QUERY function. It’s a beaut.
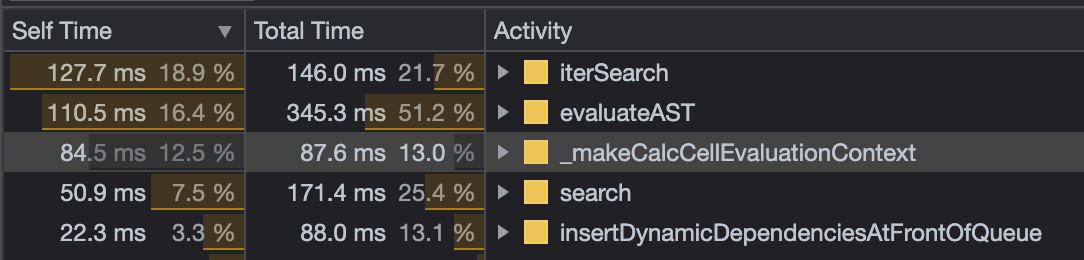
The Engine Team regularly handles customer care requests relating to bugs and performance issues in spreadsheets. Last June, I took a look at a particularly large and complicated spreadsheet where a write to a single cell caused ~12.000 cells to be recalculated. The recalculation took >700ms to execute on my machine (M1 Pro).
Profiling the recalculation, about 12.5% of the time was spent in a method called _makeCalcCellEvaluationContext.
In this post, we’ll explore the techniques I used to take this time to near zero.
GRID’s Spreadsheet Engine
Spreadsheets have a lot of use cases, ranging from budget management and attendance sheets, all the way to complex financial models. At the heart of the more complex models are dependencies. Cells depending on other cells.
- A mortgage calculator may have cells depending, directly or indirectly, on a cell representing an
Interest Rate. - In a spreadsheet to calculate marketing spend, you might instead have
Cost-per-ClickandConversion Ratevariables.
An example of what the inputs to a mortgage calculator might look like
Different scenarios are modeled by adjusting the inputs and seeing how the model reacts.
How high do the payments become when I reduce the loan term by X?
What if the interest rate rises to 9%?
For the model to “react” to changes in an input cell:
- Cells depending on the changed input cell need to be recalculated.
- To find the cell’s dependents, the model employs a dependency graph.
This cycle of recalculating dependents occurs recursively. A cell’s value changing when recalculated causes cells depending on it to be recalculated, and so forth. In the following example, every cell — except the first cell — depends on the preceding cell, forming a chain of calculations.
What you’re looking at is a GRID document, containing a graph powered by this underlying spreadsheet:
While this spreadsheet is small, more complex models often contain tens or hundreds of thousands of cells.
A single output cell is often the product of calculations encompassing dozens of thousands of cells. And the reverse: A single input cell is often used — directly or indirectly — in the majority of calculations in a spreadsheet.
The cost of recalculation
The cost of recalculation can be split into two distinct parts:
- Determining which cells to recalculate, and in which order.
- Recalculating cells.
The recalculation of cells can further be split up into the fixed cost associated with recalculating a cell, and the variable cost associated with recalculating a cell.
The variable cost is more immediately obvious: A cell invoking an expensive function like QUERY on a large dataset will take longer to recalculate than a cell adding two numbers together.
# This will take a while=QUERY(A:E, "select Name, Age where Age > 18 order by Name desc");# This will take no time at all=SUM(A1, B1)
For the most part, the variable cost is derived from how expensive the cell’s user-written formula is.
The fixed cost arises from setting up the context needed to evaluate the formula. For example, when evaluating a reference like A1, the engine needs a bit of context to know which workbook and sheet to resolve the reference to.
Given that the following formulas are written in Sheet1 in workbook.xlsx:
# Resolves to '[workbook.xlsx]Sheet1!A1'=A1# Resolves to '[workbook.xlsx]Sheet2!A1'=Sheet2!A1# Resolves to '[wb2.xlsx]Sheet3!A1'=[wb2.xlsx]Sheet3!A1
In addition to the current workbook and sheet, there’s other contextual information that the engine may require during recalculation. For example:
- When using structured references without a table name such as
[[#This row], [Value]], the engine needs to resolve the table encompassing the cell. - Because Excel and Google Sheets implement some (a lot) of functions differently, GRID has Excel and Google Sheets modes for compatibility. Spreadsheet functions need to be able to resolve the current mode to match mode-specific behaviors.
To provide this contextual information, the engine constructs an object called the evaluation context in a method called _makeCalcCellEvaluationContext. This is what we see taking 12.5% of recalculation time.
Constructing the evaluation context is done once for each cell, and the cost of doing so is the same for every cell, which constitutes the fixed cost associated with recalculating a cell.
The proportion of the total work that is spent constructing the evaluation context depends on how high the variable cost (formula evaluation) is. In workbooks with fewer, more expensive formulas, the variable cost dominates over the fixed cost.
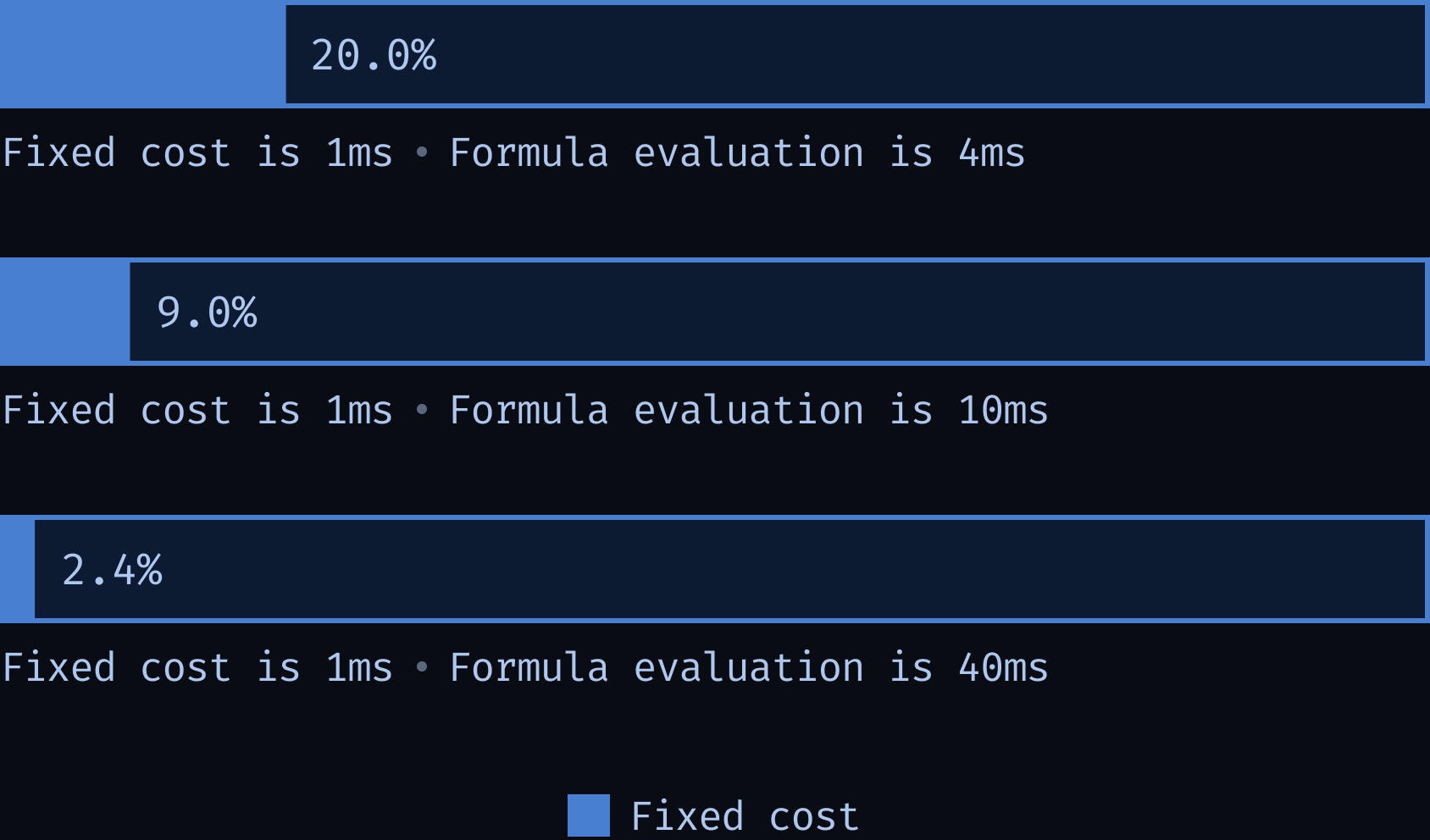
Evaluating the fixed cost
When recalculating a cell, the evaluation context is created and passed to a function that evaluates the cell’s formula (more specifically, evaluates the formula’s AST).
const ctx = this._makeCalcCellEvaluationContext(cell, ref, ...);const value = evaluateAST(cell, ctx);
The _makeCalcCellEvaluationContext method exists on the Workbook class, with the implementation along the lines of:
class Workbook implements EvaluationContext {_makeCalcCellEvaluationContext (cell: Cell, ref: Reference, ...) {// These properties and methods read the// arguments 'cell', 'ref', etc.const property1 = ...;const property2 = ...;const method1 = () => { ... };const method2 = () => { ... };// ...const evaluationContext: EvaluationContext = {...this,property1,property2,method1,method2,// ...};return evaluationContext}}
A key observation is that not all of the properties and methods are necessarily used.
Whether a piece of information is used during evaluation depends entirely on the cell’s formula, and the functions it invokes. By computing all properties ahead of time, we expend a fixed amount of effort for a variable amount of benefit.
In addition, the Workbook class is quite large, containing >30 methods and properties. Assigning those to a new object is costly.
Eliminating the fixed cost
As with any performance optimization, the solution is doing less work.
The first way to do less work is to lazily compute information, which we implemented through the use of getters.
const method1 = ...;const method2 = ...;const evaluationContext: EvaluationContext = {...this,get property1 () { ... },get property2 () { ... },method1,method2,// ...};return evaluationContext
Now we only compute properties if they’re actually used.
To avoid assigning this into a new object over and over, we created a single shared evaluation context object, encapsulated in a new CellEvaluator class.
class CellEvaluator {private evaluationContext: EvaluationContext;private cell: Cell;private ref: Reference;// ...constructor (workbook: Workbook) {const self = this;this.evaluationContext = Object.freeze({...workbook,// The getters and methods access `cell`, `ref` (etc)// via `self.{key}`get property1 () { ... },get property2 () { ... },method1 () { ... },method2 () { ... },});}evaluate (cell: Cell, ref: Reference, ...) {this.cell = cell;this.ref = ref;// ...return evaluateAST(cell, this.evaluationContext);}}
The dynamic portion of the evaluation context (cell, ref, etc) is placed into private properties on CellEvaluator, accessible via the self reference. By mutating those properties, we effectively create a new evaluation context without creating a new object instance.
By only creating a single shared evaluation context object, we avoid spreading the workbook into a new object repeatedly — which also creates less work for the garbage collector.
As a small side benefit, the code for recalculation became a tad simpler:
// Beforeconst ctx = this._makeCalcCellEvaluationContext(cell, ref, ...);const value = evaluateAST(cell, ctx);// Afterconst value = this.cellEvaluator.evaluate(cell, ref, ...);
Evaluating the impact
The Engine Team has developed a performance and regression testing suite for its spreadsheet engine. It runs on real public GRID documents, on which it performs a series of tests measuring:
- Initialization time
- Write duration (recalculation performance)
- Discrepancies (expected vs actual output)
This suite enables the Engine Team to evaluate the performance impact of changes and detect discrepancies that our unit tests might fail to detect.
Running GRID’s performance tests on this change shows that it yields, roughly, a 10% performance boost.
Proportional differences from baselineMedian -9.92%Weighted geometric mean -9.58%74.9% decreased to <0.97x, 0.92% increased to >1.03x59.8% decreased to <0.93x, 0 increased to >1.08x0.34% decreased to <0.71x, 0 increased to >1.4x0.04% decreased to <0.5x, 0 increased to >2x1% -24.3% | 10% -17.6% | 90% -0.153% | 99% +2.93%Extremes:-70.5% (from 148 ms to 43.5 ms)-52.6% (from 589 ms to 279 ms)+5.94% (from 55.4 ms to 58.7 ms)+6.60% (from 89.7 ms to 95.6 ms)
Conclusion
Aside from the positive effect this change had on GRID’s performance, I think it serves as a useful example to think about performance:
Which information do we need to evaluate now, and which can we evaluate later?
What is the fixed cost associated with performing this operation?
Do we need to do this work in the first place?
Can we cache the result of this operation? How does that impact memory usage?
Bear in mind that changes yielding a performance boost in some cases might cause degraded performance in others. Consider the worst case scenario and the circumstances under which it might occur.
As an example, the change from static properties to getters creates a worst-case scenario in which formulas repeatedly evaluate the same piece of information. This is the likely cause of the degraded performance we saw in a few documents (aside from noise). Maybe that could be mitigated with caching!
Anyway, I hope this served as an interesting read. Maybe you got some ideas that you can apply to your own code!
— Alex Harri
Big thank you to Gunnlaugur Þór Briem and Hjálmar Gíslason for reading the draft of this post and providing feedback!
PS: Check out GRID! It’s a fantastic tool for, amongst other things, building interactive documents on top of your spreadsheets.
To be notified of new posts, subscribe to my mailing list.